Each answer is used to fill in the blank of the clue beneath it
When you reach the bottom, take that answer and return to use it in clue 1
Each clue now gives a different answer and continues the Möbius process!
They use a variety of classic Cryptic wordplay tricks, so keep an eye out for Anagrams, Hidden words, Homophone, Double Definition, Assemblage, Deletion, and Reversal
Because each step relies on getting the previous answer, feel free to use the hint or reveal buttons liberally — or just click ‘Reveal All’ to explore the construction without the puzzling!
Cryptic Crosswords are my favorite form of wordplay. If you’re unfamiliar, I highly recommend The New Yorker’s introduction – they give explanations and walkthroughs.
“Unlike American-style crosswords, in which clues are usually synonyms or bits of trivia, a cryptic contains clues that are small puzzles in and of themselves. Basically, a cryptic clue consists of two elements: a definition of the answer (the so-called straight part), and a wordplay element that elliptically suggests the same answer (the cryptic portion).”
Cryptics bend your brain to parse a clue in new ways. Each word might refer to a concept or might just be a collection of letters (e.g. “Error concealed by city police” is “typo” — ‘Error’ is the straight part, and the letters t-y-p-o are concealed in order across ‘city police’.)
Quantum Puzzles have two different possible answers. One of the most famous examples is a New York Times crossword in 1996 which asked “Lead story in tomorrow’s newspaper” and all the clues were carefully constructed to accommodate either “CLINTON ELECTED” or “BOB DOLE ELECTED”. (e.g. “Black Halloween Animal” could be either ‘Cat’ or ‘Bat’, giving the C or B needed to start spelling either name.)
For reasons (long story), I started writing my own recursive cryptic sequences, where each answer gives you part of the next clue. Taking it one step further resulted in this: a Möbius Strip Quantum Cryptic Crossword sequence.
It’s not quite Quantum the same way the NYT puzzle is, where the exact same clue can give two different answers — on Side A vs Side B, the clue has a single word changed depending on what your answer to the previous question was. But even that one word change can force you to re-parse the phrase and perhaps use a different solving technique.
To get it started, the first blank has been filled in with NERD. It seemed appropriate.
Mobius Strip Cryptic Crossword
Clue 1
A strange ____ with aluminum makes a spacecraft (6)
🔑
Strange implies an anagram, aluminum is element AL
Clue 2:
🔒 #1
‘s first half breaks + gets all jumbled, now something you try to escape (7)
Anagram (jumbled) of (first half of answer + ‘gets’)
Clue 3:
In searched 🔒 #2 we argue (with some conviction) (5)
A word is hidden in consecutive letters
Clue 4:
Add it to a blade by grinding the top off a 🔒 #3 (4)
Top can mean the beginning (“from the top!”); look for a letter to take off
Clue 5:
It gives something to see when mage 🔒 #4s infrared (6)
Infrared = ‘IR’, it’s in relation to letters of ‘mage’
Clue 6:
What greets new allies post-war, as the first of 🔒 #5 stands with Ness? (8)
It starts ‘war’ – and then (post-war) you have something and ‘Ness’
Clue 7:
Help, by the sound of it maiden loses the two core parts of 🔒 #6 (4)
‘Maiden’ is just letters here, used to make a homophone for something meaning help.
Clue 8:
A lien 🔒 #7 oddly, can produce a leash (4)
Leash is the definition, there’s a way to get a synonym from the beginning of this clue (taken oddly)
Clue 9:
🔒 #8‘s first becomes its opposite; a way to spend a cozy evening in (4)
What can L stand for? What’s the opposite?
Clue 10:
It’s 🔒 #9 left aboard rowboat (4)
‘Left’ is key in this cryptic [ed: writing a double-hint for this one was tough, sorry]
Clue 11:
Tips from librarian: one other 🔒 #10 works in computer programming (4)
‘Tips’ = the sides of words, forming something which works in programming
The Super Bowl is this weekend, and you know what that means: Superb Owl! and Sportsball! memes galore. But I noticed that many of my friends who mock the sport also love strategy games like Magic the Gathering, Starcraft, or 7 Wonders — and thus I know they can appreciate a well-designed game.
There are plenty of reasons to criticize the NFL: a hypocritical position on brutal hits, stinginess in paying the refs, the exploitation of unpaid college athletes, and of course the (somewhat improving) issue of concussions and player safety.
But for my fellow nerds, here are some elements of the National Football League that you can look at on a strategic game-design level and say “Ok, that’s actually really cool.”
Nine? Elements of Football that Reflect Good Strategic Game Design
Resource Management:
Like most good games, a key component is making smart decisions about where to invest your resources.
Money:
In the NFL, the collective bargaining agreement between owners and the players’ union sets a salary cap to set a maximum (and minimum) that teams can spend each year.
Would you want to pay premium for a star or spread that salary around and upgrade more positions? It might depend on synergies with the rest of your roster. (Or you can get lucky with a player like Tom Brady who takes less money than his market value so his team can surround him with more talent.)
Rookies, as unproven quantities, are typically signed on a very affordable contract for their first few years, whereas established veterans can be much pricier. Teams are faced with the question of where they can afford to have uncertainty on their roster — contenders rarely want to risk an unproven player at quarterback, while teams that are a bit further away can take that gamble.
Time / (Plus Good Catch-up Mechanics):
In any game, there’s incentive for the person losing to resort to riskier higher-variance strategies. In football, that’s passing plays, which have a chance of gaining a lot of yards or not being caught at all. A neat aspect of football is that incomplete passes can stop the clock.
When a team is behind, time is one of the most precious resources it has, so this means the game is structured to give them every opportunity to claw their way back. Deciding when to burn time (and time-outs) is cruicial, and something even the best coaches struggle to do well.
Energy Level in Game:
This is a minor point, but one I found really neat: Playing defense tends to be more exhausting than playing offense. If an offense can run many plays in rapid succession without huddling up or substituting — and thus prevent the defense from substituting in fresh players as well — they can gain an edge over an increasingly-tired defense.
Synergies Between Players and Schemes
Building a roster
Of course, the downside of this kind of “Hurry up offense” is that the offense is also stuck with the same players on the field and doesn’t have as much time for coaches to call the next play. Teams that want to use more hurry-up offense may need to hire versatile players who can be counted on to run many types of play, and an experienced quarterback who can make smart changes on the fly.
Since players have unique skill sets, teams need to build around who’s coming out of college and who they can afford to sign. Just like putting together a Magic the Gathering or Netrunner deck to find and build on synergies, Football has fantastic interplay between skills, style, and strategy.
Finding a generational talent like Detroit’s ultra-elusive running back Barry Sanders opens up a host of new options for a team. The Detroit Lions never focused on their offensive linemen — who would try to clear the way for him — because, frankly, Barry could succeed without them. (Until he got fed up and retired early, which is a story of its own.)
If a team has a quarterback with pinpoint accuracy but a weak arm, paying for blazing fast wide receivers to race down the field and catch deep passes doesn’t make as much sense as signing shifty and precise route-runners. However, to make good use of a quarterback with a cannon-arm, fast receivers aren’t enough — he needs strong offensive linemen to protect him and give him time to throw.
There are countless interactions between strategic decisions and I love it.
Strategic Structural Asymmetries
Stadiums and Cities Matter
Even the stadium and climate in a city factor into a football team’s strategy.
Because it’s considered more difficult to pass the ball in cold and windy weather, teams in the frigid Northern divisions are more likely to focus on building a running attack and a defense that can stop the other team from running successfully. As winter approaches, they can count on the environment to limit the passing game.
However, roughly a third of teams play in indoor stadiums — eliminating the weather and the wind to make passing strategies more effective. Since half a team’s games are played at home, it has disproportionate impact on how they want to build a roster. A few stadiums even have retractable roofs, which let them decide whether to allow the elements to impact the game!
Leveraged Division Structure
An NFL division is comprised of four teams who play each other twice every season. The team in each division with the best record is guaranteed a spot in the playoffs. (Even if NONE of the teams were very good – the Washington Football Team made the playoffs this year despite losing more than half their games!)
This makes it even more crucial to plan how to counter division opponents’ schemes, and those rivalry games are usually close and exciting.
If an opposing team in your division has exceptionally tall, strong receivers you can’t afford to be caught assigning small cornerbacks to guard them. You’d need to keep that in mind when building a roster.
Well Designed Scoring System
Intermittent Scoring to Build Excitement Throughout
In the NBA, a jaw-dropping feat of athleticism… gets 2 or 3 points. Since teams average over 100 points a game, there’s a limit to how impactful any one play can be until the last minutes of a game.
On the other end of the spectrum, each score in soccer is rare and thus hugely important. Unfortunately, goals are so infrequent that historically, over 30% of English league games end with neither team scoring more than once. Those rare goals are dramatic, but personally I find it difficult to get excited about the intervening dribbling and passing when I know it’s very unlikely to shape the final result.
It’s a tradeoff, and football’s rules situate it nicely between these extremes. There are typically around 8 scoring plays each NFL game, and even the non-scoring plays are impactful (see below).
Building Progress / Tension
Getting a player on base in baseball or softball, winning a game or a set in tennis’ Game/Set/Match structure, or defeating a video game monster and getting to heal at a save point — these smaller discrete goals build toward the larger one.
Football is designed to have two key ways to make non-scoring plays significant. First, teams are only given four chances (downs) to score before they turn the ball over to the other team — but the count is reset every time they gain another 10 yards. Every third-down and fourth-down opportunity has more importance because it’s approaching that impactful mini-goal, breathing more life into a drive.
But even without this ratcheting structure, non-scoring progress matters because field position is a ‘stateful’ element which persists from one play to the next. Where one play ends, the next one begins. Every yard one team moves forward is an extra yard the opponents will need to win back. It’s a tug-of-war with scoring opportunities on the line at any time.
“Legacy” Narratives
Legacy games are all the rage, and for good reason. (Our country even decided to LARP a game of Pandemic Legacy!)
The fact that players, teams, and coaches have storylines, rivalries, and arcs is a big part of the human element to football. We’re watching some of the legends of their craft face off each week, with history between them and human motivations.
On Sunday, we get to watch completely different quarterbacks compete: young phenom Patrick Mahomes against the unaging Tom Brady. Mahomes, who won last year, is widely considered one of the best in the league despite being only 25. In contrast, Brady is 43 and amazingly this is his tenth Super Bowl appearance. He’s been playing at an elite level for decades, and he won his first Super Bowl in 2002 — when Mahomes was 6.
Most of Brady’s 20 years were spent under coach Bill Belichick, known for being brilliant and famously taciturn. (Unless, of course, you ask him about the history and minutia of football kicking rules, which makes him light up and talk for ages.) However, last year Brady decided to leave Belichick and the New England Patriots, so people were wondering whether he could succeed with a different coach. He’s answered those questions in dramatic fashion.
When storylines carry over from campaign to campaign or season to season, it’s a great way to build long narratives of meaning and importance.
Whether or not you enjoy watching the sport, there’s a lot it does well from a design perspective and I recommend anyone who enjoys strategy to try playing some of the Madden video games — how I initially got excited about the game.
You, like I, might wish to bend time and space and wake up after the election results are in. Barring an unsafe quantity of alcohol, we can’t. But second best, here are 10 Time/Space manipulation puzzle games* which can take your mind off things.
*It turns out I accidentally put 11 on the list. [Insert pun about bending the laws of arithmetic, along with time and space.]
I tried to figure out what I like about puzzle games, and I think I’m rating these for a combination of:
Of course the lines are parallel; you can tell by the way they curve away from each other.
HyperRogue is a turn-based game on a hyperbolic plane: a non-Euclidean surface in which the angles of a triangle add up to less than 180 degrees. (The opposite of being on a globe, which is non-Euclidean in that the angles of a triangle add up to MORE than 180 degrees.)
I found myself frequently getting lost but having a great time doing it.
The game itself is simple but not just window dressing for cool geometry. It’s a rogue-like game, so you’re expected to die and start over frequently. That might be best, since it keeps the focus on the experience and not on the progress or final goals.
Pro: Cool introduction to hyperbolic geometry, great way to pass some time
Cons: I found it difficult to “get good at” so I mostly wandered around and occasionally did well before being trapped by monsters.
Not normal Chess, not my 1D Chess variant, not 3D Chess. Nope. Five dimensions. I thought this was a silly gimmick at first, but the rules are surprisingly coherent, if… mindbending. The result is more logic puzzle than chess.
Treating time as a dimension that can be traversed works. A rook — which can move as far as you want in one direction — can go horizontal, vertical, or stay in the same position but go back in time. Knights (shown below) can: A) Move regularly — 2 steps and then one step horizontally/vertically B) Move two spaces horizontally/vertically and then one space back in time or C) Move two spaces back in time and then one space horizontally/vertically.
“I was playing a game against a human opponent online, and at one point they sent a queen back in time from one of the ten timelines currently in play to put five of my past kings into check at once. I sent one of my own pieces even further back to stall, and they proceeded to send one of their queens back to the start of the game to try and beat me before I even got to that point” … “If you have no idea what I just wrote, I hardly do either, this game makes my head hurt and yet eventually your mind’s eye is opened to the cosmic structure of the universe –
I’m a sucker for these self-interaction type puzzle games. Each level involves moving around, rewinding and creating one or more clones, and cooperating with… your previous self.
The game is minimalist and doesn’t have elaborate graphics or context but the puzzles themselves are intricate and clever.
Full disclosure: I haven’t finished, but what I’ve played has made me appreciate the thought that went into the design.
Pros: Great puzzles which actually use time manipulation
Cons: It’s pure puzzling without any skin or context, if you care
Monument Valley is MC Escher in a delightful little puzzle game. The puzzles themselves aren’t very difficult, but they’re not so straightforward that I found them boring. There isn’t much plot or exploration, it’s true. That’s not why you play – you play Monument Valley for the beautiful experience.
Pros: Absolutely beautiful aesthetics, delightful to play through
Cons: I wish it were longer, and while the whimsical feeling is great there isn’t much plot or exploration
The first games on the list were somewhat one-dimensional (pun intended) but we’re starting to get into games with more breadth.
In Return of the Obra Dinn, you play as an insurance agent for the East India Trading Company (stick with me.) The titular ship left with 60 people on board and returned with… none. You’re tasked with investigating what the heck happened to everyone. Someone sent you a mysterious pocketwatch which can take you back to someone’s moment of death, allowing you to hear the last few seconds and then explore the ship at that frozen time.
Imagine an interactive logic puzzle murder mystery, but there are 60 people whose fates you need to ascertain, deducing their identity based on the snippets of dialogue, their uniforms, who they hang out with, their accents and personal belongings…
I love the sense of discovery you get as you learn more about each crewmember and passenger, allowing you to go revisit earlier memories and make new deductions. In the best tradition of murder mysteries there will be new revelations which shift your understanding of things you thought you knew.
The graphics aim to evoke oldschool monitors, and somehow it works to make the game surprisingly immersive. Since the action during time-travel flashbacks are frozen, the sound design is key — and it’s fantastic. The music is amazing, and the sound effects and voice actors bring things to life… sometimes a bit too well.
Pros: Fantastic story, Clever conceit, Beautiful music, Repeated sense of dawning realization.
Cons: Given that everyone dies or disappears, things can get gruesome, especially the sounds. The graphics might not appeal to everyone.
I saw someone refer to Antichamber as “Portal on Acid” and they’re not wrong. It’s a first-person trip through an Escher-esque world where going in a circle might not lead you back to where you started.
You traverse the surreal world manipulating cubes of matter to open doors, build bridges or staircases, mark your path, or anything else you think would be helpful.
What sets Antichamber apart for me is the nonlinear element of discovery. Solving a particularly tricky puzzle can open a new area on the map, which absolutely floods my brain with dopamine.
There are a few different matter-manipulating guns you can find, each of which gives you a new capabilities and a new perspective on how to approach puzzles. I ended up revisiting placed I’d been stuck multiple times and occasionally being able to solve them — the ultimate variable interval reinforcement.
Pros: Great (very) nonlinear game, easter eggs to discover, epiphanies to have, creative puzzles which have multiple different solutions if you’re clever (or stubborn and patient).
Cons: This is an independent game and they didn’t put their focus on the graphics. While there’s a sense of progression, it isn’t plot-based.
In Contrast, you explore 1920s Noire France as a child’s imaginary friend who can transition between the regular world and the shadow realm. Unlike Lord of the Rings, this is literally your shadow — you become your 2D shadow on the wall and can jump on top of other shadows to climb somewhere new before popping back into the world of depth.
Moving the light source changes where shadows are cast on walls, creating some neat interplay between manipulating physical objects and their 2D representation.
Pros: Fantastic 1920s Noire aesthetic, creative mechanics, rewards for exploring the French city
Cons: Could be longer, and there were a couple puzzles that didn’t fit perfectly with the rest of the mechanics.
The only reason this game isn’t ranked higher in this list is that the time manipulation component is limited.
The Talos Principle has stunning graphics and music, a slowly-revealed plot about the nature and fate of humanity, conversations with an ambiguously-moral AI named Milton, a God-figure named Elohim trying to preside over a virtual world on the fritz, and of course, clever puzzles of varying difficulty.
For the most part the mechanics are straightforward: connect lasers, move boxes, unlock doors, etc (but eventually you can rewind time and solve puzzles in tandem with your previous self, my justification for putting it on this list.) The puzzles are so well designed that simple elements fit together in countless new ways, giving a fantastic depth-to-complexity ratio.
Where the game goes above and beyond is how much it rewards exploration and experimentation. Not only are the worlds filled with easter eggs, they also contain a more challenging set of “star” puzzles which often require you to think outside the box — finding clever ways to bring equipment from one puzzle into another, creating a staircase to get on top of a wall you thought was irrelevant, discovering an extra block tucked away in the bushes… I love it.
Pros: Beautiful graphics and music, a wide variety of non-repetitive puzzles, rewards for exploring and being creative.
Cons: While most of the puzzles are purely about figuring out the solution, a few require fast reactions/controls. It can be frustrating to know exactly what to do but not quite be able to do it.
In Fez, you play as a character in a 2D world who is granted the ability to see the third dimension. Once you can look at the world from different directions, you realize that some platforms are closer together than you thought — just in a different dimension. What had looked like a simple line is actually a detailed wall with a door. A stick is really a sign with cryptic symbols from ancient civilizations.
The graphics aren’t impressive, but the worldbuilding sure is. Because things aren’t always obvious until you’ve looked at them from different perspectives, there are countless secrets tucked away and a surprising amount of thought put into the backstory.
As I explored, I found myself scribbling little notes and codes down on scraps of paper that slowly took over my desk. Over and over, I pieced together hints that gave me a new understanding of what had been in front of me all along. I’ve heard the phrase “Epiphany addiction” and it seems wholly appropriate for Fez.
Pros: Clever mechanics, huge nonlinear world, impressive amount of lore and worldbuilding, numerous perspective-shifts, tons of hidden secrets
Cons: The huge nonlinear world actually deterred me at first — I wasn’t sure where to go and put the game down for a while before being convinced to give it a second try.
Honorable Mentions:
Before getting to the Top 2 Time/Space Manipulation Puzzle Games, here are quick-hit puzzlers that didn’t quite make this list:
The Swapper: Create clones and swap your consciousness between them to solve puzzles. Great game by the makers of Talos Principle, but didn’t have enough time/space manipulation to make the cut.
The Witness: Another beautiful game which I consider the spiritual successor to Myst. But I couldn’t quite justify putting it on the list without more of a time/space connection.
The Bridge: I should love this game. It’s MC Escher and time-manipulation and neat graphics and everything I like! …but the controls were a bit too “floaty” for me and I found it frustrating. Your mileage may vary.
OneShot: Doesn’t so much break the fourth wall as stroll through where you expected the fourth wall to be, and starts complementing your furniture. There’s some elements of time travel but not really time manipulation.
TimeSpinner: A great Metroidvania game where you jump between the past and present, and can stop time mid-battle to get better positioning. It has the time-manipulation, but not the “puzzle game” part.
Baba Is You: The most meta of all games. You alter the logical rules of your world by changing the words that spell the rules out. You might win by setting “Wall is floating” and go under it, or “Wall is You” and turn into the wall, moving around to get to the goal.
On its face it’s a simple platformer where you jump on monsters and collect puzzle pieces. Oh, and you can rewind time to undo if you miss a jump.
Oh, and then later you can keep some objects going forward in time while you go backward. Oh, and in some levels time will go forward when you move to the right and backward when you move left. And later you can make time move at different speeds in different parts of the map. Oh, and then… Somehow the different mechanics aren’t gimmicks – the puzzles actually work.
It also features the best “Backward Time” levels I’ve seen: Depending on where you’re standing, a dead monster either died because it fell into a pit of spikes or because you jumped on it. Both timelines are coherent, and allow you to change where the monster came from, as long as he ends up dead at the end.
Pair that with beautiful graphics, a wonderful classical soundtrack that was chosen to be interesting at different speeds both forward and backward, and some hidden super-difficult puzzles, and you have one of my favorite games ever.
Pros: Great puzzles with the best time-manipulation mechanics, great graphics, great soundtrack.
Cons: There’s more of an aesthetic than a plot, and some people find it pretentious. I played with a controller, but wonder if playing on a keyboard would be difficult.
Portal 1 was a fantastic game, and Portal 2 was somehow even better. I don’t think it can be called a cult classic anymore now that it’s so popular, but it’s the source of lines like “The cake is a lie.”
There are so many good things to say I’ll just rattle them off:
Innovative physics-warping mechanics
Fantastic puzzles which increase in difficulty at a good pace
Hilarious writing
Exciting plot
Great graphics and soundtrack
A long single-player campaign
An entirely separate two-player Cooperative campaign!
An online community which has generated its own puzzles, adding even more value
Pros: Everything above.
Cons: It’s a first-person puzzle game, requiring use of a controller or a keyboard/mouse. This is only a problem because I keep recommending the game to people who aren’t usually into video games, but think they’d love Portal anyway.
If you’ve heard of the Birthday Paradox and/or like math puzzles and/or want to know how it connects with Computational Genomics and the Seven Bridges of Konigsberg, this is for you.
The Birthday Paradox (which would be more accurately named The Birthday Somewhat Unintuitive Result) asks “How many people do you need in a group before there’s a 50% chance that at least two share a birthday?”
It’s easier to flip it around and ask “For a given number of people, what are the chances that NONE of them share a birthday?” This makes it simpler: each time we add another person to the group, we just need to calculate the number of “open” birthdays and multiply by the odds of our new member having one of those.
P(no shared birthdays for n people) =
If we just keep increasing n and calculating the probability, we find that with 23 people there’s a 50% chance of at least two people sharing a birthday.
(Ok, technically we answered “Given a number of people what probability…” and used brute force instead of “Given a probability what number of people…” but let’s ignore that; everyone else does.)
How about if we want to know the probability that no THREE people in a group share a birthday?
This variant is trickier, and has tripped up many smart people. Do you think you can solve it?
Give it a shot! I’ll talk about the solution after some context for why it matters and some graphics/tools made with Wolfram Mathematica. I started as a machine learning research scientist with Wolfram earlier this year and I’ve been really enjoying playing with the tools!
Birthdays, Bridges, de Bruijn Graphs, and… Bgenomics
This is more than an idle math puzzle; it’s related to a fascinating challenge in Computational Genomics. (It was actually a question on my homework in grad school.)
When we want to read a DNA sequence, it’s usually far too long for our machines to process all at once. Instead, we copy the sequence a bunch, slice the copies up, and gather all the pieces of a chosen, more manageable, length — say, 4 base pair “letters”.
In the end, we know every length-four subsection in our DNA sequence, we just don’t know their order. For example, if we had a length-7 sequence and took all the random chunks of 4, we might end up with
TACA, ATTA, GATT, TTAC
Now, as though it were a one-dimensional jigsaw puzzle, we try to piece them together. Each chunk of 4 will overlap with its neighbors by 3 letters: the chunk ATTA ends with TTA, so we know the next chunk must start with TTA. There’s only one which does — TTAC — so those pieces fit together as ATTAC. Now we look for a piece that begins with TAC, and so on.
In our case, there’s only one unique way to arrange the five chunks:
GATTACA
As the sequences get longer, scientists turn to graph theory to find this arrangement. Treating each DNA chunk as an edge, we can form a directed graph indicating which chunks could follow (overlap with) each other.
This overlapping-ness graph is called a De Bruijn Graph, and if there’s a path which uses every edge exactly once, we’ve done it: we’ve found a way to order the DNA chunks and reconstruct the larger sequence!
If this sounds a bit like the Seven Bridges of Konigsberg problem, there’s a reason — it’s the same issue. It’s as though we were walking from “overlap island” to “overlap island”, each time saying to ourselves “Ok, if I have a piece ending in GCA, what bridge-chunk could come next?” and hoping to find a path that uses every chunk.
Since Euler solved the Bridges of Konigsberg problem, this type of path — using every edge exactly once — is known as an Eulerian Path. The great thing is that we have really efficient algorithms to find them!
However, we can run into trouble if some of our “overlap” sections aren’t distinct. If a section of DNA is repeated, that’s ok — we can probably still find the Eulerian Path through the graph.
…But if a section of the original DNA repeats three times, we’re screwed. When the repeat is at least as long as our “overlap” we can no longer find a unique path — multiple Eulerian Paths exist.
Let’s take the sequence AACATCCCATGGCATTT, in which the phrase “CAT” repeats three times. Once we reach the “ACAT” chunk, we don’t know what comes next. Overlapping with chunk “CATT” would lead us straight to the end — leaving out many chunks — so we know that comes last. But the loops starting either CATG or CATC could come next.
So, if we’re going to read a long DNA sequence, we might ask:
How many overlapping chunks of 4 can we take before there’s a 50% or a 5% or 1% chance that we see a triple-repeat which ruins our attempt to reconstruct the original?
This is where we return to our Birthday Paradox variant!
Back to the Birthday Problem
With our Birthday Problem, there are 365 different birthdays a person can have. With DNA chunks of 4, there are 64 different three-letter ways each chunk could end. If any three chunks have the same ending, we won’t know how to reconstruct our sequence.
As the chunks get longer, we have a much better chance of producing a unique Eulerian Path from our graph.
While we can’t move the Earth farther from the Sun (nor should we (probably)) to increase the number of possible birthdays in a year, we CAN use chunks larger than 4 and increase the number of ways each chunk can end. So if we know we’re sequencing a genome 100,000 letters long, how long do our chunks need to be in order for us to have a >99% chance of reconstructing it?
Since starting my job at Wolfram Research, I’ve been playing with their graph capabilities and put together this little interactive tool. It generates a random gene and shows the De Bruijn Graph when you take chunks of different lengths. It’s amazing how quickly a totally chaotic graph becomes more orderly!
(The cloud-deployment can be a bit sluggish, but give it a second after clicking a button. If you get the desktop version of Wolfram Mathematica you can play with things like this incredibly quickly. They’re so cool.)
The Answer
Heck if I know. Sorry.
I can get the right answer of about 88 by running simulations, but I didn’t manage to derive the general formula for my class.
Every time I’ve shown this question to a friend — and the first time I saw it on my Computational Genomics homework — the response has been “Oh, this is simple. You just… wait, no, that won’t work. We can just… well… hm.”
In the original version, there’s a unique situation — each person has different birthdays. But in our version, for 23 people:
each person could have distinct birthdays
one pair could share a birthday and the other 21 are distinct
two pairs could share birthdays and the other 19 are distinct
three pairs could share birthdays and the other 17 are distinct
…
eleven pairs could share birthdays and the last one is distinct
For each scenario, we need to calculate the number of ways it can occur, the probability of each, and how it impacts our chance of getting a triple. It’s a mess.
But enough of my complaining about an old homework problem I never solved and which I’m clearly over and never think about.
How did you approach the problem? Did you solve it? Let me know!
Personal note: In my continuing efforts against Perfectionism, I’m going to declare this done. It’s taken up real estate in my head long enough.
Chess is sometimes held up as the embodiment of strategy and brilliance — if you’re playing chess while your opponent is playing checkers, you’re out-thinking them. Those even smarter can play chess in higher dimensions, with 3-D chess often used as a metaphor for politics. (There’s even a 5-D chess game on Steam which looks mind-bending.)
But going the other direction, the existence of 5-D, 3-D, and 2-D chess made me wonder: is there a way 1-D chess could work? And be fun, that is.
I’m not the first to have this thought; many people have tried their hand at designing one-dimensional chess including the late great Martin Gardner. His approach was for each side to have a single King, Knight, and Rook at the ends of an eight-tile long board. With so few pieces and spaces it’s fairly easy to “solve” the game, mapping out every possible move the same way we can solve tic-tac-toe.
I set out to create 1-D Chess which kept the spirit of the game as much as possible. It was initially inspired by conversations with Brienne years ago about designing mobius chess (which is topologically identical to playing on a loop, but is *obviously* cooler.)
Values to Preserve
Low complexity – Piece moves are simple, there are few rules
High depth – Many games are possible, with a mix of strategy and tactics
Full information – No fog of war, no hidden cards, no randomness
Personalized openings – Different opening play/counter-play options to match your aesthetics and strengths.
The last one is contentious — I know many people bemoan the amount of memorization required to learn the various chess openings. Bobby Fischer even famously proposed Fischer Random Chess which randomized the back row each game, thus stripping the game down to a player’s ability to understand the situation and respond.
However, I happen to enjoy the way you can study various opening strategies and say “I prefer to use the Alapin Variation to counter the Accelerated Dragon Sicilian Defense — I hate ceding the middle of the board.” Being able to steer the game toward your preferred style before getting into tactical elements of the game is a key part of what makes a game feel like *chess* to me.
So, after a lot of brainstorming and a lot of rejected ideas — see the last section — I whittled it down to a few core concepts. Pictures are worth a thousand words (although I’m sure there are opportunities for arbitrage somewhere…) so here’s a screenshot of the game I started building in Tabletop Simulator:
My Proposal for 1D Chess
Ring Board – 28 squares; the outside of a standard chess board
12 Pieces per side – 4 fewer pawns, but otherwise the same pieces
Placement Control – Players take turns placing non-pawns in their region to set up
Ring Board
Look, nobody said it had to be a line segment. Since each square has exactly two neighbors and the entire board is connected, it counts as 1-D. Put it into polar coordinates if you have to.
Using a 28-square ring allows us to keep the standard chess board, but it also allows much more depth of play without adding complexity to the rules. Like in 2-D chess, you can focus your attack on one side or the other, and you have the ability to try interrupting your opponent’s plans by striking and causing havoc on the other side of the fight.
12 Pieces, Simple Moves
Similarly, I stuck with the original pieces and kept their movement as close in spirit as I could:
Pawn: Move forward one or capture two spaces ahead, ignoring the square in front. Cannot turn around.
Bishop: Moves up to 6 spaces, 2 at a time (hopping over every other square).
Rook: Moves up to 3 spaces forward, 1 at a time. [EDIT: Because the Rooks slide instead of hop, they get stuck easily. My current solution is that they can move *though* the King.]
Knight: Jumps either 3 or 5 squares
Queen: Can move like the Rook or Bishop
King: Moves one square.
This move set creates parallels to the 2-D version: Bishops stay on their color, pawns can get locked together, and Knights have a unique move (5 squares) that not even the Queen has.
The moves themselves stay fairly simple, but allow the kind of interplay that I like in 2-D chess with pieces defending each other and getting in each other’s way.
Opening Placement
Each player has 12 opposite squares to start, with 2 on each end filled by pawns. The remaining 8 squares are up to the players to arrange.
Starting with White, the players take turns placing one of their pieces on an empty square between their pawns.
It’s up to you: You can choose to create an unbalanced attack with both Knights on one side, ready to jump over the pawns and storm the enemy. You can choose to put your Bishops on the inside, where they have an easier time of getting out, or on the outside so that the Rooks are the last line of defense to mop up any attacks. You can leave the King with the Queen — your strongest piece — or between two Rooks…
There are lots of possibilities which rely on how you enjoy playing and how your opponent seems to be setting up. While the complexity of this rule is low, it adds immense depth to the game and prevents it from being quite so easily “solved”.
By requiring the pawns to take up the outermost two spaces, initial move choices are limited to advancing a pawn or using a Knight to hop over them. Moving one pawn can give your Bishops or Queen a way to move through them and enter the fray. This is all just like in the 2-D version in a way I find aesthetically very pleasing.
If you prefer to just focus on the tactical side of things, you can use the normal ordering or give both players mirrored random arrangements.
Ideas that I considered but didn’t use:
Here are some snippets of ideas that I had but rejected because the complexity/depth tradeoff wasn’t good enough, or the game strayed too far and stopped being recognizable as “Chess”.
Making pieces face a direction, limiting them to moving forward
Allowed to turn around if the square immediately in front of them is filled
Might allow rules that make it easier to capture pieces from the back
Pieces can only capture certain types of pieces (in either a rock-paper-scissors style or Stratego style)
Ranged attacks without moving
Allow pieces to swap with each other
Either upon landing on your own, or as a type of movement
Pieces that push or pull rather than capture
Pieces that move differently when next to certain others
Rooks launch pawns, for example
The Queen could move in the pattern of any piece in a contiguous chain with her
Different terrain
Mud tiles which must be stopped on
Rocky terrain which prevents knights from landing on it
Pieces spawn new pieces next to them as an action
What do you think? Ideas and opinions are welcome!
I struggle with perfectionism. Well, not so much “struggle with” — I’m f*cking great at it. It comes naturally.
There are some upsides, but perfectionism is also associated with anxiety, depression, procrastination, and damaged relationships. Perhaps you, like I, have spent far too much time and emotional energy making sure that an email had the right word choice, had no typos, didn’t reuse a phrase in successive sentences/paragraphs, and closed with the ‘correct’ sign-off. (‘Best,’ is almost always optimal, by the way).
“If I couldn’t do something that rated 10 out of 10 — or at least close to that — I didn’t want to do it at all. Being a perfectionist was an ongoing source of suffering and unhappiness for me … Unfortunately, many of us have been conditioned to hold ourselves to impossible standards. This is a stressful mind state to live in, that’s for sure.” ~ Tony Bernard J.D.
The topic of perfectionism confused me for years. Of course you want things to be perfect; why would you ever actively want something to be worse? However, there’s way more to it than that: It’s a complex interplay between effort, time, motivation, and expectations.
Far too many self-help recommendations essentially said “Be ok with mediocrity!” which… did not speak to me, to say the least.
To better understand the concept, I went through a number of books and papers before building a quasi-mathematical model. You know, like ya’do.
I’ve come to see perfectionism as a mindset with a particular calibration between the quality of your work and your emotional reaction — with decreased sensitivity to marginal differences in lower-quality work and increasing sensitivity as the quality goes up.
In a “Balanced” mindset,you become happier in linear proportion to how much better your work is going. (y = x)
In a “Satisficing” mindset — taking a pass/fail test, for example — you care about whether something is “good enough”. Most of your emotional variance comes as you approach and meet that threshold. ( e^x / (1+e^x) )
In a Perfectionist mindset, the relationship between quality and emotion is polynomial. You feel almost equally bad about scoring a 40% on a test vs. a 65%, but the difference between a 90% and 93% looms large. (y = x^7)
Looking at the model, I realized it could explain a number of experiences I’d had.
Why even small tasks seem daunting to a perfectionist
A common experience with a perfectionist mindset is having trouble ‘letting go’ of a project — we want to keep tinkering with it, improving it, and never feel quite comfortable moving on. (I don’t want to say how long this draft sat around.)
This make sense given the model:
When I think about clicking ‘send’ or ‘post’ before I’ve checked for typos, before I’ve reread everything, before considering where it might be wrong or unclear… it just feels, well, WRONG. I’m not yet happy with it and have trouble declaring it done.
Apart from requiring more time and effort, this can make even seemingly trivial tasks feel daunting. Internally, if you know that a short email will take an hour and a half it’s going to loom large even if you have trouble explaining quite why such a small thing is making you feel overwhelmed.
What’s helped me: A likely culprit is overestimating the consequences of mistakes. One solution is to be concrete and write down what you expect to happen if it turns out you have a typo, miss a shot, or bomb a test. Sometimes all it takes to readjust is examining those expectations consciously. Other times you’ll need to experience the ‘failure’, at which point you can compare it to your stated expectations.
Why perfectionists give up on hobbies and tasks easily
Another way to look at this is: if you don’t expect to reach high standards, a project just doesn’t seem worth doing.
The result is a kind of min-max of approach to life: If you can’t excel, don’t bother spending time on it.
That’s not necessarily a bad thing!
However, we don’t always have control. In my nonprofit communications career, I sometimes got assigned to write press releases on topics that *might* get attention, but which seemed not newsworthy to me. It may have still been worth the few hours of my time in case it grabbed a reporter’s eye. It was important to keep my job. But I had so. much. trouble. getting myself to do the work.
Even in the personal realm, picking up a new hobby is made difficult. If it doesn’t seem like you’re going to be amazing at it, the hobby as a whole loses its luster.
What’s helped me: A big problem for me has been overlooking the benefits gained from so-called “failure”. Once I start to factor in e.g. how much I expect to learn (so that I can do better in the future) I end up feeling much better about giving things a shot.
Why procrastination (and anxiety) are common
At a granular scale, the problem becomes worse. Rather than “How good do I expect to feel at the end of this?” our emotional reaction is probably trained by the in-the-moment “How much happier do I expect to feel as a result of one more bit of work?”
In other words, we can view the derivative/slope of these graphs as motivation:
With a perfectionist mindset, the bigger and further away a goal is, the more difficult it will be to feel motivated in the moment. For much of the time, we’re trying to push ourselves to work without getting any internal positive reinforcement.
This is a particular issue in the Effective Altruism movement where the goal is to *checks notes* Save the World. Also, to (“Figure out how to do the most good, and then do it.”)
It’s true that as a perfectionist nears their goal, they’re extremely motivated! But that also means that the stakes are very high for every decision and every action. …Which is a recipe for anxiety. Terrific.
What’s helped me: To the extent that I can, I find that breaking tasks into pieces helps. If I think of my goal as “Save the World”, another day of work won’t feel very important. But a goal of “Finish reading another research paper” is something I can make real progress on in a day!
All models are wrong, but some are useful
This framework isn’t perfect. Neither is this writeup. (I’m hyper-aware.) But this idea has been in my head, in my drafts folder, and unfinished for months. Rather than give in to the sense that I “should” keep working on it, I’m going to try following my own advice. I’m remembering that:
I’ve clarified my thinking a ton by writing everything down.
The consequences of a sloppy post in are minimal in the big scheme of things.
This isn’t supposed to be my final conclusion – it’s one step on the path
Even if it’s not perfect, perhaps the current iteration of this framework can help you understand me, yourself, or perfectionists in your life.
I used to have this “DONE IS BETTER THAN PERFECT” poster draped over a chair in my office. I never got around to hanging it up, but honestly? It seems better that way.
If I gave you 10,000 random numbers between 0 and 1, how precisely could you estimate pi? It’s Pi Approximation Day (22/7 in the European format), which seems like the perfect time to share some math!
When we’re modeling something complex and either can’t or don’t want to bother to find a closed-form analytic solution, we can find a way to get close to the answer with a Monte Carlo simulation. The more precisely we want to estimate the answer, the more simulations we would create.
One classic Monte Carlo approach to find pi is to treat our 10,000 numbers as the x and y coordinates of 5,000 points in a square between (0,0) and (1,1). If we draw a unit circle at (0,0), the percent of the points which land inside the circle gives us a rough estimate of the area – which should be pi / 4. Multiply by 4, and we have our estimate.
This technique works, but it’s not the most precise. There’s a fair bit of variance – a 95% confidence interval is about .09 units wide, from 3.12 to 3.21. Can we do better?
Another way to find the quarter-circle’s area is to treat it as a function and take its average value. (Area is average height times width, the width is 1, so the area inside the quarter-circle is just its average height.) That would give us pi/4, so we multiply by 4 to get our estimate for pi.
We have 10,000 random numbers between 0 and 1; all we have to do is calculate f(x) for each and take the mean:
This gives us a more precise estimate; the 95% confidence interval is less than half what it was!
But we can do better.
Antithetic Variates
What happens if we take our 10,000 random numbers and flip them around? They’re just a set of points uniformly distributed between 0 and 1, so (1-x) is also a set of points uniformly distributed between 0 and 1. If the expected value of f(x) is pi with variance 0.1, then the expected value of f(1-x) should also be pi with variance of 0.1.
So how does this help us? It looks like we just have two different ways to get the same level of precision.
Well, if f(x) is particularly high, then f(1-x) is going to be particularly low. By pairing each random number with its converse , we can offset some of the error and get an estimation more closely centered around the true mean. Taking the average of two distributions, each with the same expected value should still give us the same answer.
(This trick, known as using antithetic variates, doesn’t work with every function, but works here because the function f(x) always decreases as x increases.)
Lo and behold, our 95% confidence interval has narrowed down to 0.013, still only using 10,000 random numbers!
To be fair, this only beats 22/7 about 30% of the time with 10,000 random simulations. Can we reliably beat the approximation without resorting to more simulations?
Control Variates
It turns out we can squeeze a bit more information out of those randomly generated numbers. If we know the exact expected value for a part of the function, we can be more deliberate about offsetting the variance. In this case, let’s use c(x)=x^2 as our “control variate function”, since we know that the average value of x^2 from 0 to 1 is exactly 1/3.
Where our simulated function was
now we add a term that will have an expected value of 0, but will help reduce variance:
For each of our 10,000 random x’s, if x^2 is above average, we know that f(x) will probably be a bit *below* average, and we nudge it up. If x^2 is below average, we know f(x) is likely a bit high, and nudge it down. The overall expected value doesn’t change, but we’re compressing things even further toward the mean.
The constant ‘b’ in our offset term determines how much we ‘nudge’ our function, and is estimated based on how our control variate covaries with the target function:
(In this case, b is about 2.9) Here’s what we get:
See how the offset flattens our new function (in orange) to be tightly centered around 3.14?
This is pretty darn good. Without resorting to more simulations, we reduced our 95% confidence interval to 0.006. This algorithm gives a closer approximation to pi than 22/7 about 57% of the time.
If we’re not bound by the number of random numbers we generate, we can get as close as we want. With 100,000 points, our control variates technique has a 95% confidence interval of 0.002, and beats 22/7 about 98% of the time.
These days, as computing power gets cheaper, we can generate 100,000 or even 1,000,000 random numbers with no problem. That’s what makes simulations so versatile – we can find ways to simulate even incredibly complicated processes and unbounded functions, deciding how precise we need to be.
Happy Pi Approximation Day!
(You may ask, why is there a “Pi Approximation Day” and not a “Pi Simulation Day”? Well, according to Nick Bostrom, every day is Simulation Day. Probably.)
In football, it pays to be unpredictable (although the “wrong way touchdown” might be taking it a bit far.) If the other team picks up on an unintended pattern in your play calling, they can take advantage of it and adjust their strategy to counter yours. Coaches and their staff of coordinators are paid millions of dollars to call plays that maximize their team’s talent and exploit their opponent’s weaknesses.
That’s why it surprised Brian Burke, formerly of AdvancedNFLAnalytics.com (and now hired by ESPN) to see a peculiar trend: football teams seem to rush a remarkably high percent on 2nd and 10 compared to 2nd and 9 or 11.
What’s causing that?
His insight was that 2nd and 10 disproportionately followed an incomplete pass. This generated two hypotheses:
Coaches (like all humans) are bad at generating random sequences, and have a tendency to alternate too much when they’re trying to be genuinely random. Since 2nd and 10 is most likely the result of a 1st down pass, alternating would produce a high percent of 2nd down rushes.
Coaches are suffering from the ‘small sample fallacy’ and ‘recency bias’, overreacting to the result of the previous play. Since 2nd and 10 not only likely follows a pass, but a failed pass, coaches have an impulse to try the alternative without realizing they’re being predictable.
These explanations made sense to me, and I wrote about phenomenon a few years ago. But now that I’ve been learning data science, I can dive deeper into the analysis and add a hypothesis of my own.
The following work is based on the play-by-play data for every NFL game from 2002 through 2012, which Brian kindly posted. I spend some time processing it to create variables like Previous Season Rushing %, Yards per Pass, Yards Allowed per Pass by Defense, and QB Completion percent. The Python notebooks are available on my GitHub, although the data files were too large to host easily.
Irrationality? Or Confounding Variables?
Since this is an observational study rather than a randomized control trial, there are bound to be confounding variables. In our case, we’re comparing coaches’ play calling on 2nd down after getting no yards on their team’s 1st down rush or pass. But those scenarios don’t come from the same distribution of game situations.
A number of variables could be in play, some exaggerating the trend and others minimizing it. For example, teams that passed for no gain on 1st down (resulting in 2nd and 10) have a disproportionate number of inaccurate quarterbacks (the left graph). These teams with inaccurate quarterbacks are more likely to call rushing plays on 2nd down (the right graph). Combine those factors, and we don’t know whether any difference in play calling is caused by the 1st down play type or the quality of quarterback.
The classic technique is to train a regression model to predict the next play call, and judge a variable’s impact by the coefficient the model gives that variable. Unfortunately, models that give interpretable coefficients tend to treat each variables as either positively or negatively correlated with the target – so time remaining can’t be positively correlated with a coach calling running plays when the team is losing and negatively correlated when the team is winning. Since the relationships in the data are more complicated, we needed a model that can handle it.
I saw my chance to try a technique I learned at the Boston Data Festival last year: Inverse Probability of Treatment Weighting.
In essence, the goal is to create artificial balance between your ‘treatment’ and ‘control’ groups — in our case, 2nd and 10 situations following 1st down passes vs. following 1st down rushes. We want to take plays with under-represented characteristics and ‘inflate’ them by pretending they happened more often, and – ahem – ‘deflate’ the plays with over-represented features.
To get a single metric of how over- or under-represented a play is, we train a model (one that can handle non-linear relationship better) to take each 2nd down play’s confounding variables as input – score, field position, QB quality, etc – and tries to predict whether the 1st down play was a rush or pass. If, based on the confounding variables, the model predicts the play was 90% likely to be after a 1st down pass – and it was – we decide the play probably has over-represented features and we give it less weight in our analysis. However, if the play actually followed a 1st down rush, it must have under-represented features for the model to get it so wrong. Accordingly, we decide to give it more weight.
After assigning each play a new weight to compensate for its confounding features (using Kfolds to avoid training the model on the very plays it’s trying to score), the two groups *should* be balanced. It’s as though we were running a scientific study, noticed that our control group had half as many men as the treatment group, and went out to recruit more men. However, since that isn’t an option, we just decided to count the men twice.
Testing our Balance
Before processing, teams that rushed on 1st down for no gain were disproportionately likely to be teams with the lead. After the re-weighting process, the distributions are far much more similar:
Much better! They’re not all this dramatic, but lead was the strongest confounding factor and the model paid extra attention to adjust for it.
For each potential confounding variable, we take the difference in means between plays following 1st down passes and 1st down rushes and adjust for their combined variance. A high standard difference of means indicates that our two groups are dissimilar, and in need of balancing. The standardized differences had a max of around 47% and median of 7.5% before applying IPT-weighting, which reduced the differences to 9% and 3.1%, respectively.
Actually Answering Our Question
So, now that we’ve done what we can to balance the groups, do coaches still call rushing plays on 2nd and 10 more often after 1st down passes than after rushes? In a word, yes.
In fact, the pattern is even stronger after controlling for game situation. It turns out that the biggest factor was the score (especially when time was running out.) A losing team needs to be passing the ball more often to try to come back, so their 2nd and 10 situations are more likely to follow passes on 1st down. If those teams are *still* calling rushing plays often, it’s even more evidence that something strange is going on.
Ok, so controlling for game situation doesn’t explain away the spike in rushing percent at 2nd and 10. Is it due to coaches’ impulse to alternate their play calling?
Maybe, but that can’t be the whole story. If it were, I would expect to see the trend consistent across different 2nd down scenarios. But when we look at all 2nd-down distances, not just 2nd and 10, we see something else:
If their teams don’t get very far on 1st down, coaches are inclined to change their play call on 2nd down. But as a team gains more yards on 1st down, coaches are less and less inclined to switch. If the team got six yards, coaches rush about 57% of the time on 2nd down regardless of whether they ran or passed last play. And it actually reverses if you go beyond that – if the team gained more than six yards on 1st down, coaches have a tendency to repeat whatever just succeeded.
It sure looks like coaches are reacting to the previous play in a predictable Win-Stay Lose-Shift pattern.
Following a hunch, I did one more comparison: passes completed for no gain vs. incomplete passes. If incomplete passes feel more like a failure, the recency bias would influence coaches to call more rushing plays after an incompletion than after a pass that was caught for no gain.
Before the re-weighting process, there’s almost no difference in play calling between the two groups – 43.3% vs. 43.6% (p=.88). However, after adjusting for the game situation – especially quarterback accuracy – the trend reemerges: in similar game scenarios, teams rush 44.4% of the time after an incomplete and only 41.5% after passes completed for no gain. It might sound small, but with 20,000 data points it’s a pretty big difference (p < 0.00005)
All signs point to the recency bias being the primary culprit.
Reasons to Doubt:
1) There are a lot of variables I didn’t control for, including fatigue, player substitutions, temperature, and whether the game clock was stopped in between plays. Any or all of these could impact the play calling.
2) Brian Burke’s (and my) initial premise was that if teams are irrationally rushing more often after incomplete passes, defenses should be able to prepare for this and exploit the pattern. Conversely, going against the trend should be more likely to catch the defense off-guard.
I really expected to find plays gaining more yards if they bucked the trends, but it’s not as clear as I would like. I got excited when I discovered that rushing plays on 2nd and 10 did worse if the previous play was a pass – when defenses should expect it more. However, when I looked at other distances, there just wasn’t a strong connection between predictability and yards gained.
One possibility is that I needed to control for more variables. But another possibility is that while defenses *should* be able to exploit a coach’s predictability, they can’t or don’t. To give Brian the last words:
But regardless of the reasons, coaches are predictable, at least to some degree. Fortunately for offensive coordinators, it seems that most defensive coordinators are not aware of this tendency. If they were, you’d think they would tip off their own offensive counterparts, and we’d see this effect disappear.
You could say that Donald Trump has a… distinct way of speaking. He doesn’t talk the way other politicians do (even ignoring his accent), and the contrast between him and Clinton is pretty strong. But can we figure out what differentiates them? And then, can we find the most… Trump-ish sentence?
That was the challenge my friend Spencer posed to me as my first major foray into data science, the new career I’m starting. It was the perfect project: fun, complicated, and requiring me to learn new skills along the way.
To find out the answers, read on! The results shouldn’t be taken too seriously, but they’re amusing and give some insight into what might be important to each candidate and how they talk about the political landscape. Plus, it serves to demonstrate the data science techniques I’m learning for as a portfolio project.
If you want to play with the model yourself, I also put together an interactive javascript page for you: you can test your judgment compared to its predictions, browse the most Trumpish/Clintonish sentences and terms, and enter your own text for the model to evaluate.
To read about how the model works, I wrote a rundown with both technical and non-technical details below the tables and graphs. But without further ado, the results:
The Trump-iest and Clinton-est Sentences and Phrases from the 2016 Campaign:
Clinton
Trump
Top sentence: “That’s why the slogan of my campaign is stronger together because I think if we work together and overcome the divisiveness that sometimes sets americans against one another and instead we make some big goals and I’ve set forth some big goals, getting the economy to work for everyone, not just those at the top, making sure we have the best education system from preschool through college and making it affordable and somp[sic] else.” — Presidential Candidates Debate
Top sentence: “As you know, we have done very well with the evangelicals and with religion generally speaking, if you look at what’s happened with all of the races, whether it’s in south carolina, i went there and it was supposed to be strong evangelical, and i was not supposed to win and i won in a landslide, and so many other places where you had the evangelicals and you had the heavy christian groups and it was just — it’s been an amazing journey to have — i think we won 37 different states.” — Faith and Freedom Coalition Conference
Defining the problem: What makes a sentence “Trump-y?”
I decided that the best way to quantify ‘Trump-iness’ of a sentence was to train a model to predict whether a given sentence was said by Trump or Clinton. The Trumpiest sentence will be the one that the predictive model would analyze and say “Yup, the chance this was Trump rather than Clinton is 99.99%”.
Along the way, with the right model, we can ‘look under the hood’ to see what factors into the decision.
Technical details:
The goal is to build a classifier that can distinguish between the candidate’s sentences optimizing for ROC_AUC, and allows us to extract meaningful/explainable coefficients.
Gathering and processing the data:
In order to train the model, I needed large bodies of text from each candidate. I ended up scraping transcripts from events on C-SPAN.org. Unfortunately, they’re uncorrected closed caption transcripts and contained plenty of typos and misattributions. On the other hand, they’re free.
I did a bit to clean up some recurring problems like the transcript starting every quote section with “Sec. Clinton:” or including descriptions like [APPLAUSE] or [MUSIC]. (Unfortunately, they don’t reliably mark the end of the music, and C-SPAN sometimes claims that Donald Trump is the one singing ‘You Can’t Always Get What You Want.’)
Technical details:
I ended up learning to use Python’s Beautiful Soup library to identify the list of videos C-SPAN considers campaign events by the candidates, find their transcripts, and grab only the parts they supposedly said. I learned to use some basic regular expressions to do the cleaning.
My scraping tool is up on github, and is actually configured to be able to grab transcripts for other people as well.
Converting the data into usable features
After separating the large blocks of text into sentences and then words, I had some decisions to make. In an effort to focus on interesting and meaningful content, I removed sentences that were too short or too long – “Thank you” comes up over and over, and the longest sentences tended to be errors in the transcription service. It’s a judgement call, but I wanted to keep half the sentences, which set cutoffs at 9 words and 150 words. 34,108 sentences remained.
A common technique in natural language processing is to remove the “stopwords” – common non-substantive words like articles (a, the), pronouns (you, we), and conjunctions (and, but). However, following James Pennebaker’s research, which found these words are surprisingly useful in predicting personality, I left them in.
Now we have what we need: sequences of words that the model can consider evidence of Trump-iness.
Technical details:
I used NLTK to tokenize the text into sentences, but wrote my own regular expressions to tokenize the words. I considered it important to keep contractions together and include single-character tokens, which the standard NLTK function wouldn’t have done.
I used a CountVectorizer from sklearn to extract ngrams and later selected the most important terms using a SelectFromModel with a Lasso Logistic Regression. It was a balance – more terms would typically improve accuracy, but water down the meaningfulness of each coefficient.
I tested using various additional features, like parts of speech and lemmas (using the fantastic Spacy library) and sentiment analysis (using the Textblob library) but found that they only provided marginal benefit and made the model much slower. Even just using 1-3 ngrams, I got 0.92 ROC_AUC.
Choosing & Training the Model
One of the most interesting challenges was avoiding overfitting. Without taking countermeasures, the model could look at a typo-riddled sentence like “Wev justv don’tv winv anymorev.” and say “Aha! Every single one of those words are unique to Donald Trump, therefore this is the most Trump-like sentence ever!”
I addressed this problem in two ways: the first is by using regularization, a standard machine learning technique that penalizes a model for using larger coefficients. As a result, the model is discouraged from caring about words like ‘justv’ which might only occur two times, since they would only help identify those couple sentences. On the other hand, a word like ‘frankly’ helps identify many, many sentences and is worth taking a larger penalty to give it more importance in the model.
The other technique was to use batch predictions – dividing the sentences into 20 chunks, and evaluating each chunk by only training on the other 19. This way, if the word ‘winv’ only appears in a single chunk, the model won’t see it in the training sentences and won’t be swayed. Only words that appear throughout the campaign have a significant impact in the model.
Technical details:
The model uses a logistic regression classifier because it produces very explainable coefficients. If that weren’t a factor, I might have tried a neural net or SVM (I wouldn’t expect a random forest to do well with such sparse data.) In order to set the regularization parameters for both the final classifier and for the feature-selection Lasso Logistic Regressor, I used sklearn’s cross-validated gridsearch object, optimizing for ROC_AUC.
During the prediction process, I used a stratified Kfold to divide the data in order to ensure each chunk would have the appropriate mix of Trump and Clinton sentences. It was tempting to treat the sentences more like a time series and only use past data in the predictions, but we want to consider how similar old sentences are to the whole corpus.
Interpreting and Visualizing the Results:
The model produced two interesting types of data: how likely the model thought each sentence was spoken by Trump or Clinton (how ‘Trumpish’ vs. ‘Clintonish’ it is), and how any particular term impacts those predicted odds. So if a sentence is predicted to be spoken by Trump with estimated 99.99% probability, the model considers it extremely Trumpish.
The term’s multipliers indicate how each word or phrase impacts the predicted odds. The model starts at 1:1 (50%/50%), and let’s say the sentence includes the word “incredible” – a Trump multiplier of 7.42. The odds are now 7.42 : 1, or roughly 88% in favor of Trump. If the model then sees the word “grandmother” – a Clinton multiplier of 6.12 – its estimated odds become 7.42 : 6.12, (or 1.12 : 1), roughly 55% Trump. Each term has a multiplying effect, so a 4x word and 2x word together have as much impact as an 8x word – not 6x.
Technical details:
In order to visualize the results, I spent a bunch of time tweaking the matplotlib package to generate a graph of coefficients, which I used for the pronouns above. I made sure to use a logarithmic scale, since the terms are multiplicative.
In addition, I decided to teach myself enough javascript to learn to use the D3 library – allowing interactive visualizations and the guessing game where players can try to figure out who said a given random sentence from the campaign trail. There are a lot of ways the code could be improved, but I’m pleased with how it turned out given that I didn’t know any D3 prior to this project.
The idea of a coming-of-age ceremony has always been a bit strange to me as an atheist. Sure, I attended more than my fair share of Bat and Bar Mitzvahs in middle school. But it always struck me as odd for us to pretend that someone “became an adult” on a particular day, rather than acknowledging it was a gradual process of maturation over time. Why can’t we just all treat people as their maturity level deserves?
The same goes with weddings – does a couple’s relationship really change in a significant way marked by a ceremony? Or do two people gradually fall in love and grow committed to each other over time? Moving in with each other marks a discrete change, but what does “married” change about the relationship?
But my thinking has been evolving since reading this fantastic post about rituals by Brett and Kate McKay at The Art of Manliness. Not only do the rituals acknowledge a change, they use psychological and social reinforcement to help the individuals make the transition more fully:
One of the primary functions of ritual is to redefine personal and social identity and move individuals from one status to another: boy to man, single to married, childless to parent, life to death, and so on.
Left to follow their natural course, transitions often become murky, awkward, and protracted. Many life transitions come with certain privileges and responsibilities, but without a ritual that clearly bestows a new status, you feel unsure of when to assume the new role. When you simply slide from one stage of your life into another, you can end up feeling between worlds – not quite one thing but not quite another. This fuzzy state creates a kind of limbo often marked by a lack of motivation and direction; since you don’t know where you are on the map, you don’t know which way to start heading.
…
Just thinking your way to a new status isn’t very effective: “Okay, now I’m a man.” The thought just pings around inside your head and feels inherently unreal. Rituals provide an outward manifestation of an inner change, and in so doing help make life’s transitions and transformations more tangible and psychologically resonant.
Brett and Kate McKay cover a range of aspects of rituals, but I was particular struck by the game theory implications of these ceremonies. By coordinating society’s expectations in a very public manner, transition rituals act like traffic lights to make people feel comfortable and confident in their course of action.
The Value of Traffic Lights
Traffic lights are a common example in game theory. Imagine that you’re driving toward an unmarked intersection and see another car approaching from the right. You’re faced with a decision: do you keep going, or brake to a stop?
If you assume they’re going to keep driving, you want to stop and let them pass. If you’re wrong, you both lose time and there’s an awkward pause while you signal to each other to go.
If you assume they’re going to stop, you get to keep going and maintain your speed. Of course, if you’re wrong and they keep barreling forward, you risk a deadly accident.
Things go much more smoothly when there are clear street signs or, better yet, a traffic light coordinating everyone’s expectations.
Ceremonies as Traffic Lights
Now, misjudging a teenager’s maturity is unlikely to result in a deadly accident. But, with reduced stakes, the model still applies.
As a teen gets older, members of society don’t always know how to treat him – as a kid or adult. Each type of misaligned expectations is a different failure mode: If you treat him as a kid when he expected to be treated as an adult, he might feel resentful of the “overbearing adult”. If you treat him as an adult when he was expecting to be treated as a kid, he might not take responsibility for himself.
A coming-of-age ritual acts like the traffic light to minimize those failure modes. At a Bar or Bat Mitzvah, members of society gather with the teenager and essentially publicly signal “Ok everyone, we’re switching our expectations… wait for it… Now!”
“In common knowledge, not only does A know x and B know x, but A knows that B knows x, and B knows that A knows x, and A knows that B knows that A knows x, ad infinitum.”
If you weren’t sure that the oncoming car could see their traffic light, it would be almost as bad as if there were no light at all. You couldn’t trust your green light because they might not stop. Not only do you need to know your role, but you need to know that everyone knows their role and trusts that you know yours… etc.
Public ceremonies gather everyone to one place, creating that common knowledge. The teenager knows that everyone expects him to act as an adult, society knows that he expects them to treat him as one, and everyone knows that those expectations are shared. Equipped with this knowledge, the teen can count on consistent social reinforcement to minimize awkwardness and help him adopt his new identity.
Obviously, these rituals are imperfect – Along with the socially-defined parts of identity, there are internal factors that make someone more or less ready to be an adult. Quite frankly, setting 13 as the age of adulthood is probably too young.
But that just means we should tweak the rituals to better fit our modern world. After all, we have precise engineering to set traffic light schedules, and it still doesn’t seem perfect (this XKCD comes to mind).
That’s what makes society and civilization powerful. We’re social creatures, and feel better when we feel comfortable in our identity – either as a child or adult, as single or married, as grieving or ready to move on. Transition rituals serve an important and powerful role in coordinating those identities.
We shouldn’t necessarily respect them blindly, but I definitely respect society’s rituals more after thinking this through.
Three in the morning, Dad, good citizen
stopped, waited, looked left, right.
He had been driving nine hundred miles,
had nearly a hundred more to go,
but if there was any impatience
it was only the steady growl of the engine
which could just as easily be called a purr.
I chided him for stopping;
he told me our civilization is founded
on people stopping for lights at three in the morning.

















 If we just keep increasing n and calculating the probability, we find that with 23 people there’s a 50% chance of at least two people sharing a birthday.
If we just keep increasing n and calculating the probability, we find that with 23 people there’s a 50% chance of at least two people sharing a birthday.




 Chess is sometimes held up as the embodiment of strategy and brilliance — if you’re playing chess while your opponent is playing checkers, you’re out-thinking them. Those even smarter can play chess in higher dimensions, with 3-D chess often used as a metaphor for politics. (There’s even a
Chess is sometimes held up as the embodiment of strategy and brilliance — if you’re playing chess while your opponent is playing checkers, you’re out-thinking them. Those even smarter can play chess in higher dimensions, with 3-D chess often used as a metaphor for politics. (There’s even a 






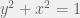

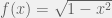





 In football, it pays to be unpredictable (although the “
In football, it pays to be unpredictable (although the “





 You could say that Donald Trump has a… distinct way of speaking. He doesn’t talk the way other politicians do (even ignoring his accent), and the contrast between him and Clinton is pretty strong. But can we figure out what differentiates them? And then, can we find the most… Trump-ish sentence?
You could say that Donald Trump has a… distinct way of speaking. He doesn’t talk the way other politicians do (even ignoring his accent), and the contrast between him and Clinton is pretty strong. But can we figure out what differentiates them? And then, can we find the most… Trump-ish sentence?



